include_graphics("https://www.desarrollosocialyfamilia.gob.cl/storage/image/banner-saludmental.png")
Completar hasta as 11:59 PM del martes, 7 de noviembre de 2023
El objetivo de esta guía práctica es explicar el formato del informe de los trabajos del curso. Ya que la elaboración de los informes incluye analisis en R, la idea es poder aprovechar los recursos existentes para poder realizar escritura y análisis en un mismo documento. La base de esto son los prácticos sobre Reportes Dinámicos 1 y Reportes Dinámicos 2, donde se describieron las estructura de carpetas y archivos, así como también el lenfuage RMarkdown, que permite vincular análisis en R con escritura en Markdown.
Para facilitar el desarrollo de los trabajos en este entorno ponemos a disposición una carpeta que se puede bajar aquí. Esta carpeta está basada en el protocolo IPO, mencionado en el práctico Reportes Dinámicos 1, con la siguente estructura de archivos y carpetas:
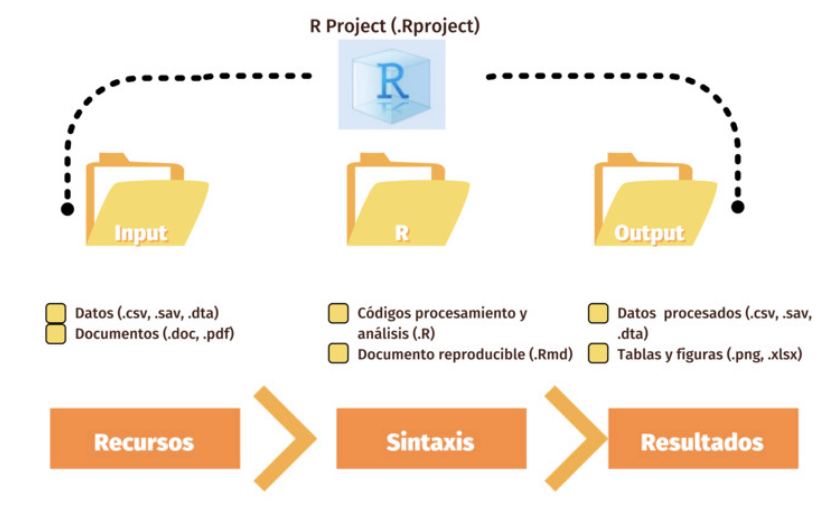
Donde el flujo de trabajo es el siguiente:
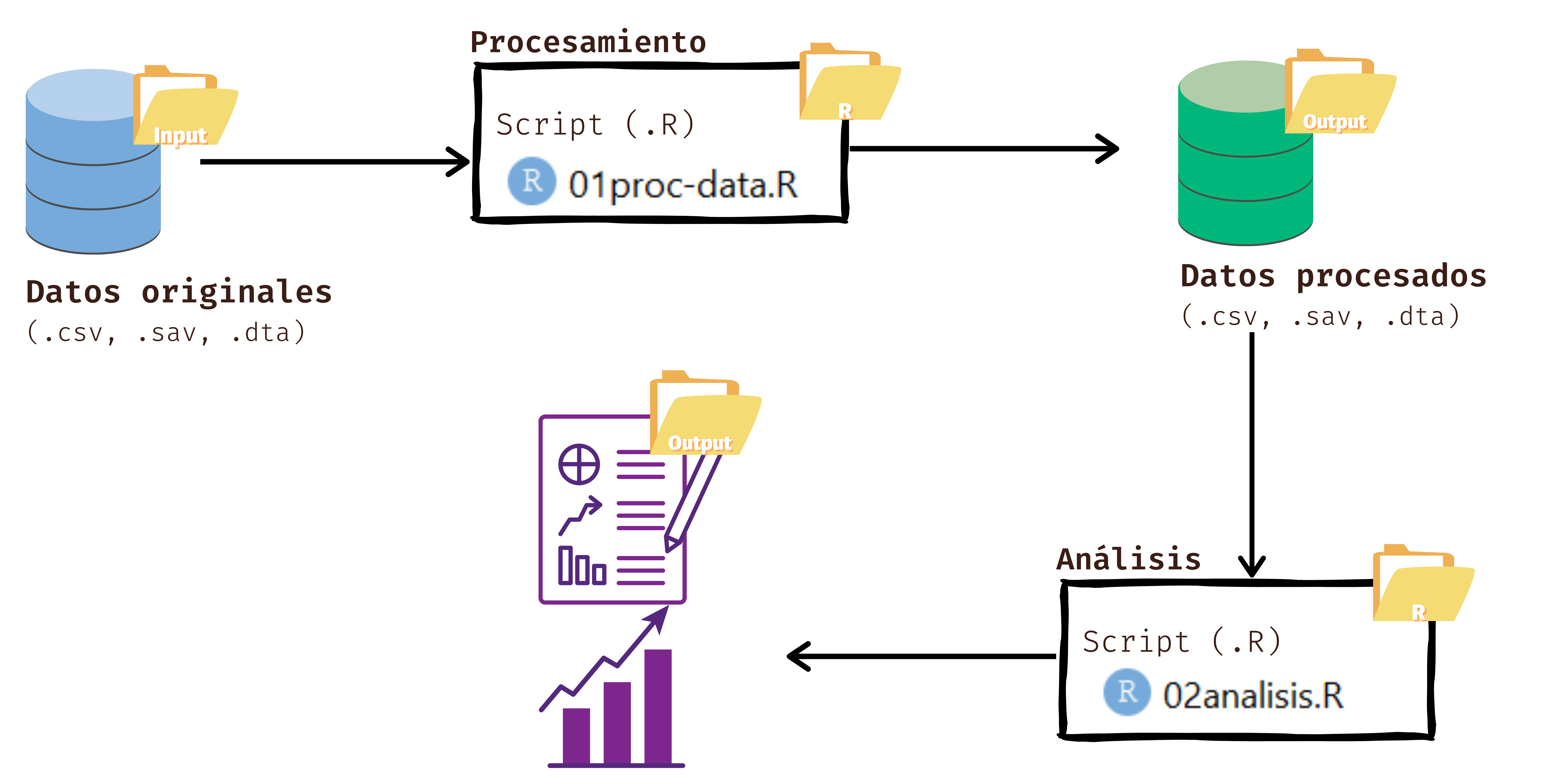
En detalle, aprenderemos los siguientes contenidos:
Para los ejemplos de esta plantilla utilizaremos la encuesta ELSOC, pero como sabemos, el trabajo se realiza con la encuesta CASEN.
Quarto es un sistema de publicación técnico y científico de código abierto. Es un lenguaje para crear y formatear documentos, similar a Markdown, aunque más general, con nuevas características y capacidades.
No es exclusivo de R, también funciona con Python, Julia, y Observable.
Como R Markdown, Quarto usa knitr para ejcutar códigos de R, y por lo tanto es capaz de renderizar la mayor parte de los archivos .Rmd sin necesidad de hacer modificaciones. Es así como lo que hemos hecho con R Markdown funciona en Quarto, sin embargo, el uso de Quarto se ha masificado en el último tiempo, con su mayor amplitud de recursos.
El nombre de Quarto viene del formato de un libro o panfleto producido a partir de hojas completas impresas con ocho páginas de texto, cuatro en cada lado, que luego se pliegan dos veces para producir cuatro hojas. Las hojas se recortan a lo largo de los pliegues para producir ocho páginas de libro. Cada página impresa se presenta como un cuarto del tamaño de la hoja completa.
El libro impreso más antiguo de Europa conocido es un quarto, el Sibyllenbuch, que se cree que fue impreso por Johannes Gutenberg en 1452-53, antes de la Biblia de Gutenberg, y que sobrevive solo como un fragmento.
Lo que nos remite a las ideas de ciencia abierta y a la posibilidad de universalizar el conocimiento.
Para generar un documento Quarto hacemos lo siguiente:

Para comenzar, definiremos los elementos que van en el encabezado (front matter o YAML), al menos debemos especificar:
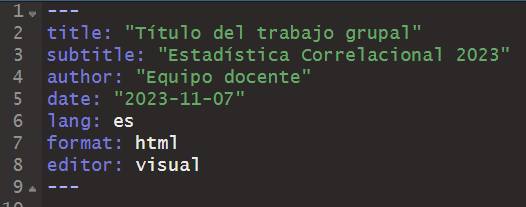
Con ese YAML el encabezado se ve de la siguiente forma:

Para los títulos de los apartados deben poner un # antes del nombre, y para los subapartados cada vez más pequeños dos o más #.
Por ejemplo, si ponemos:
# Variables
## Descripción de variables
Los apartados y subapartados diferirán en su tamaño y se verán de esta forma.

Si quisiéramos poner una imagen, lo ideal es llamarla desde la web:
Recordemos que si no queremos que se vea un chunk, en las options debemos poner
echo=FALSE.
include_graphics("https://www.desarrollosocialyfamilia.gob.cl/storage/image/banner-saludmental.png")
O desde la carpeta local  o con:
include_graphics("../files/banner-saludmental.png")
El procesamiento de datos lo realizaremos en un archivo de sintaxis proc_data.R, que alojaremos en la carpeta de procesamiento.
Las librerías que utilizaremos en esta guía práctica son:
library(pacman)
pacman::p_load(tidyverse, # manipulacion datos
sjPlot, # tablas
confintr, # IC
gginference, # visualizacion
rempsyc, # reporte
broom, # varios
sjmisc, # para descriptivos
knitr) # para
options(scipen = 999) # para desactivar notacion cientifica
rm(list = ls()) # para limpiar el entorno de trabajoComo señalamos antes, cargaremos los datos del Estudio Longitudinal Social de Chile (ELSOC) para ejemplificar. En esta guía práctica llamaremos los datos desde la web, pero en la carpeta del proyecto se encuentran alojados en la carpeta input/data, y se llama de la siguiente forma:
load("input/data/ELSOC_Long.RData")
Pero, para llamar la base de datos desde la web:
load(url("https://dataverse.harvard.edu/api/access/datafile/7245118"))Realizaremos un tratamiento simple de los casos:
# Filtrar casos y seleccionar variables
data <- elsoc_long_2016_2022.2 %>%
filter(ola==1) %>%
select(sexo=m0_sexo,edad=m0_edad,nedu=m01,
s11_01,s11_02,s11_03,s11_04,s11_05,s11_06,s11_07,s11_08,s11_09)
# remover NA's
data <- data %>%
set_na(., na = c(-888, -999)) %>%
na.omit()
# crear variable nueva
data <- data %>%
rowwise() %>%
mutate(sint_depresivos = mean(c(s11_01,s11_02,s11_03,s11_04,s11_05,s11_06,s11_07,s11_08,s11_09))) %>%
ungroup()Guardamos la base de datos procesada en la carpeta de output, con
saveRDS(data, "output/data.Rdata")
En este apartado pueden poner su introducción, de acuerdo con la pauta del trabajo que se encuentra disponible en el enlace.
En este ejemplo daremos una mirada a la salud mental, y exploraremos posibles asociaciones con la edad, sexo y nivel educacional.
En este apartado pueden poner sus variables, de acuerdo con la pauta del trabajo que se encuentra disponible en el enlace.
A continuación, en nuestro ejemplo describiremos las variables necesarias para responder a nuestro objetivo.
En este ejemplo, se seleccionaron las variables:
Y las variables del módulo de Salud y Bienestar, referentes a Estado de ánimo: sintomatología depresiva, con nivel de medición ordinal, los ítems son los siguientes:
Podemos caargar los datos en nuestro informe sin que se vea poniendo la option
echo=FALSE:data <-readRDS("output/data.RData").
tab1 <- data %>%
group_by(sexo) %>% # agrupamos por sexo
summarise(n = n()) %>% # contamos por categ de respuesta
mutate(prop = round((n / sum(n)) * 100, 2)) # porcentaje
pm <- as.numeric(tab1[2,3])
ph <- as.numeric(tab1[1,3])
tabla1 <- tab1 %>%
kableExtra::kable(format = "html",
align = "c",
col.names = c("Sexo", "n", "Proporción"),
caption = "Tabla 1. Distribución de sexo") %>%
kableExtra::kable_classic(full_width = FALSE, position = "center", font_size = 14) %>%
kableExtra::add_footnote(label = "Fuente: Elaboración propia en base a ELSOC 2016.")En la Tabla 1 podemos ver que la proporción de mujeres que responde la encuesta corresponde a 60.12%, mientras que la propoción de hombres corresponde a 39.88%.
tabla1| Sexo | n | Proporción |
|---|---|---|
| 1 | 1151 | 39.88 |
| 2 | 1735 | 60.12 |
| a Fuente: Elaboración propia en base a ELSOC 2016. |
En las options del chunk desde el que llamamos a la tabla le ponemos
tbl-nombre tablapara etiquetarla, y luego en el texto ponemos@tbl-nombre-tablapara referenciarla. También, cuando queremos llamar un valor, es necesario asignarlo a un objeto, y en el texto lo llamamos con:

En este apartado pueden poner sus análisis, de acuerdo con la pauta del trabajo que se encuentra disponible en el enlace.
En nuestro ejemplo, analizaremos la correlación entre algunas variables.
cor_edad_dep <- cor(data$edad, data$sint_depresivos)
cor_nedu_dep <- cor(data$nedu, data$sint_depresivos)
cor_nedu_edad <- cor(data$nedu, data$edad)g1 <- data %>%
group_by(nedu) %>%
summarise(sint_dep = mean(sint_depresivos, na.rm = T),
edad=mean(edad, na.rm = T))
grafico1 <- ggplot(data = g1,
mapping = aes(x = sint_dep, y = edad, label = nedu)) +
geom_point() +
geom_smooth(method = "lm",colour = "black",fill="lightblue",size=0.5) +
labs(x = "Sintomatología depresiva",
y = "Edad",
caption = "Fuente: Elaboración propia en base a ELSOC 2026") +
theme_bw()En la Figura 1 es posible apreciar… La correlación entre la edad y el promedio de la sintomatología depresiva corresponde a 0.0176236.
grafico1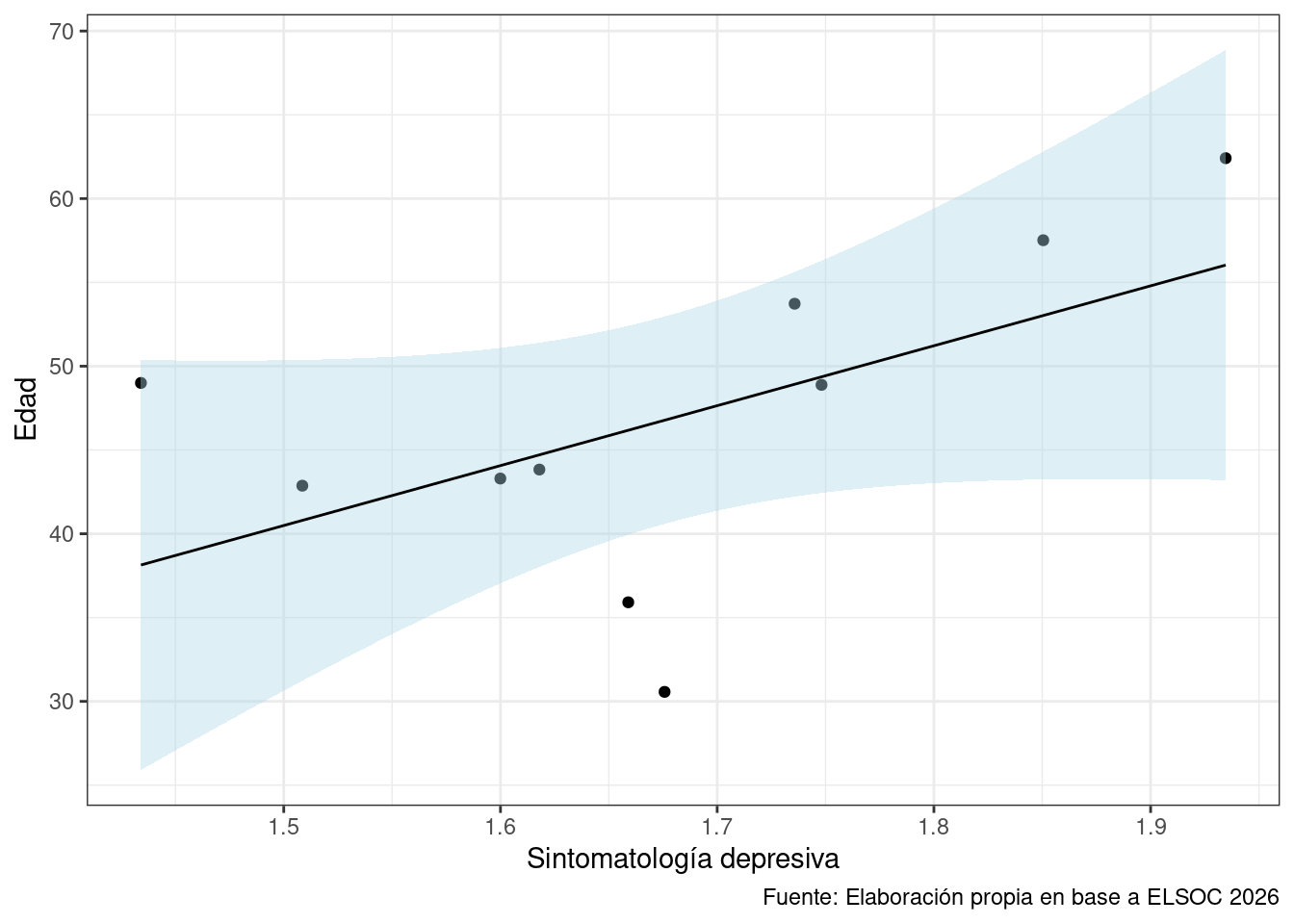
En las options del chunk desde el que llamamos a la figura le ponemos
fig-nombre figurapara etiquetarla, y luego en el texto ponemos@fig-nombre-figurapara referenciarla.
En este apartado pueden poner sus conclusiones, de acuerdo con la pauta del trabajo que se encuentra disponible en el enlace.
Aquí redactamos algunas conclusiones.
En este apartado pueden poner su bibliografía, de acuerdo con la pauta del trabajo que se encuentra disponible en el enlace.
Ponemos un - para generar un listado.
COES (2023). Radiografía del Cambio Social: Análisis de Resultados Longitudinales ELSOC 2016-2022. Presentación de Resultados COES. Marzo, Santiago de Chile.
R Core Team (2023). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/.
Finalmente, podemos ver el informe que hemos creado en este enlace.
Completar el reporte de progreso correspondiente a esta práctica aquí. El plazo para contestarlo es hasta el día martes de la semana siguiente a la que se publica la práctica correspondiente.