pacman::p_load(tidyverse, # Manipulacion datos
haven, # Importar datos
sjmisc, # Descriptivos
sjlabelled) # Etiquetas
options(scipen = 999) # para desactivar notacion cientifica
rm(list = ls()) # para limpiar el entorno de trabajoBonus track: Trabajando con CASEN y EBS
Completar hasta as 11:59 PM del jueves, 26 de octubre de 2023
Presentación
En este guía práctica se presentan recomendaciones para trabajar de manera más eficiente con la Encuesta CASEN 2022. Además, se presenta el código para poder vincular la Encuesta de Bienestar Social (EBS) con la Encuesta CASEN en Pandemia 2020 para aquellos grupos que quieran utilizar ambas fuentes de información.
Encuesta de Caracterización Socioeconómica (CASEN)
Para la evaluación final, utilizaremos la Encuesta de Caracterización Socioeconómica CASEN en su última versión 2022. Sin embargo, dado el tamaño de esta base de datos, nuestro trabajo puede dificultarse ya sea porque nuestro ordenador no tenga la suficiente capacidad para procesar cálculos con la base completa, como para trabajar colaborativamente en nuestros grupos. Para sortear esta dificultad, aquí presentamos algunos pasos que permiten obtener una base de datos más liviana con la cual trabajar.
Al igual que para la evaluación final, en esta guía seguiremos el flujo de trabajo reproducible basado en el protócolo IPO. Para aprender de qué se trata el prótolo IPO, revisar este práctico anterior.
Paso 1. Descargar CASEN 2022
Ingresamos a la página del Observatorio Social del MDSF y en la pestaña de “Encuestas” elegimos CASEN, y en el menú izquierdo de “Años” seleccionamos 2022. Luego, en la pestaña “Bases de datos” descargamos la base en alguno de los dos formatos disponibles (.sav de SPSS o .dta de Stata). También se recomienda descargar el Libro de Códigos respectivo y manuales metodológicos asociados.
Esta base de datos las alojamos en la carpeta local input > datos de nuestro proyecto.
Paso 2. Procesamiento en R
Para acortar el tamaño de la base de datos, pasaremos por un procesamiento breve en la que buscaremos seleccionar solo las variables que utilizaremos y, de ser el caso, aplicar los filtros necesarios a los casos.
Comencemos por preparar nuestros datos. Iniciamos cargando las librerías necesarias.
Luego, importamos la base CASEN 2022 desde nuestra carpeta local.
casen <- haven::read_dta("input/datos/Base de datos Casen 2022 STATA.dta") Exploramos los datos.
names(casen)
dim(casen)Ahora, seleccionamos las variables que nos interesan para nuestra investigación. Además, y solo en caso de que nuestro estudio requiera trabajar con cierta fracción de la población, podemos aplicar un filtro para acortar aún más la base.
casen_recorte <- casen %>%
# seleccionamos ---
select(1:3, hogar, nucleo, varunit, varstrat, expr,
edad, sexo, s5, educ, activ, y1,
ytrabajocor, pobreza_multi_5d, o15) %>%
# filtramos ---
filter(activ == 1) En este ejemplo, seleccionamos determinadas variables de interés y nos quedamos solo con las personas ocupadas o que se encuentran empleadas (activ == 1).
Verifiquemos ahora la base resultante.
names(casen_recorte) [1] "id_vivienda" "folio" "id_persona" "hogar"
[5] "nucleo" "varunit" "varstrat" "expr"
[9] "edad" "sexo" "s5" "educ"
[13] "activ" "y1" "ytrabajocor" "pobreza_multi_5d"
[17] "o15" dim(casen_recorte)[1] 85710 17Ahora, guardamos esta base CASEN recortada en la carpeta output > datos de nuestro proyecto con un nombre que nos permita identificarla y diferenciarla de la base original. Esta base la guardaremos en formato .RData, que es más liviano que otros formatos.
save(casen_recorte, file = "output/datos/casen2022_recortada.RData")Por último, limpiamos de nuestro enviroment la base CASEN 2022 original para alivinar memoria y borramos de nuestra carpeta local la base de datos original ubicada en input > datos para así ahorrar espacio en nuestro proyecto y ordenador.
rm(casen) # borramos del enviromentDe aquí en más, para nuestros futuros procesamientos y análisis debemos solo llamar a esta base casen2022_recortada, y no más a la original.
Vinculación de la EBS 2021 con CASEN 2020
También existe la posibilidad de usar la Encuesta de Bienestar Social (EBS) del año 2021 en vinculación con la encuesta CASEN. Para esto, hay que tener en consideración que la EBS 2021 es una submuestra de la Casen en Pandemia 2020, por lo que si se quiere emplear variables que pertenecen a la EBS en conjunto con variables de CASEN, solo se puede utilizar la correspondiente versión del año 2020 de esta última.
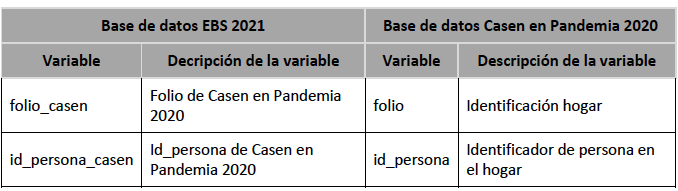
Para poder vincular la información de la persona entrevistada y contenida en la Base de datos de la EBS y la información de la persona en la Base de datos de Casen en Pandemia 2020, se debe utilizar la variable de identificación del hogar de Casen (folio_casen) y la variable de identificación de la persona en el hogar Casen (id_persona_casen), contenidas ambas también en la Base de datos de la EBS 2021.
De esta manera, la llave que permite un identificador único a nivel de persona es: folio_casen id_persona_casen. Cabe destacar, que antes de realizar la vinculación, se debe homologar el nombre de estas dos variables en ambas bases de datos.
Luego de realizar la vinculación, se sugiere verificar que el universo de la base de datos resultante corresponda a 10.921 personas.
Factores de expansión
Respecto a los factores de expansión al vincular la EBS 2021 con CASEN en Pandemia 2020, se debe utilizar la variable fexp proveniente de la EBS, ya que este factor es representativo para esta encuesta.
Para revisar mayor información respecto a la vinculación de ambas bases, revisar aquí.
Veamos como hacerlo en R.
Paso 1. Descargar ambas bases
Este paso ya lo hicimos antes, solo que ahora debemos descargar dos bases de datos distintas. La documentación asociada a estas bases de datos y la descripción de las variables que contienen, se encuentra disponible en el Libro de Códigos elaborados para dicha finalidad, el que puede ser descargado conjuntamente con la bases de datos.
Ingresamos a la página del Observatorio Social del MDSF y en la pestaña de “Encuestas” elegimos Encuesta de Bienestar y CASEN en Pandemia, respectivamente. Luego, en la pestaña “Bases de datos” descargamos la base en alguno de los dos formatos disponibles (.sav de SPSS o .dta de Stata). También se recomienda descargar el Libro de Códigos respectivo y manuales metodológicos asociados.
Ambas bases de datos las alojamos en la carpeta local input > datos de nuestro proyecto.
Paso 2. Procesamiento en R
Al igual que con CASEN 2022, la CASEN en Pandemia 2020 es una base de datos pesada, por lo que se recomienda realizar primero el paso 2 de la sección anterior, seleccionando las variables de interés y filtrando los casos que correspondan de ser el caso. Recuerda que, una vez terminado este paso, borra la CASEN en Pandemia 2020 original para ahorrar memoria en nuestro ordenador.
Comencemos por preparar nuestros datos. Iniciamos cargando las librerías necesarias.
pacman::p_load(tidyverse, # Manipulacion datos
haven, # Importar datos
sjmisc, # Descriptivos
sjlabelled) # Etiquetas
options(scipen = 999) # para desactivar notacion cientifica
rm(list = ls()) # para limpiar el entorno de trabajoLuego, importamos nuestra CASEN 2020 recortada y la EBS 2021.
load(file = "output/datos/casen2020_recorte.RData")
ebs <- haven::read_dta(file = "input/datos/Base de datos EBS 2021 STATA.dta")Como mencionamos antes, debemos renombrar las variables folio e id_persona de la base CASEN 2020 recortada para poder unirla con la EBS 2021.
casen <- casen %>%
rename(folio_casen = folio,
id_persona_casen = id_persona)
names(casen) # verificamos [1] "folio_casen" "id_persona_casen" "id_vivienda" "region"
[5] "hogar" "expr" "expp" "expc"
[9] "varstrat" "varunit" "sexo" "y1" Para unir ambas bases de datos, usaremos la función left_join() del paquete dplyr. En esta función, ponemos a la izquierda la base de datos a la que queremos que se le agrege información y a la derecha la base de datos desde la cual proviene la información. Además, debemos proveer un argumento que indica el nombre de las variables que servivarán como llave (es decir, que están presentes en ambas bases).
datos_proc <- left_join(ebs, casen, by = c("folio_casen", "id_persona_casen")) # unimos
datos_proc %>%
head() # verificamos# A tibble: 6 × 263
folio folio_casen id_persona_casen region.x provincia comuna zona
<dbl> <dbl> <dbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+l>
1 10002 110110010301 118 1 [1 Región … 11 [11 I… 1101 [Iqu… 1 [Urb…
2 10003 110110020301 409 1 [1 Región … 11 [11 I… 1101 [Iqu… 1 [Urb…
3 10004 110110030201 454 1 [1 Región … 11 [11 I… 1101 [Iqu… 1 [Urb…
4 10008 110110031801 1050 1 [1 Región … 11 [11 I… 1101 [Iqu… 1 [Urb…
5 10009 110110040501 1121 1 [1 Región … 11 [11 I… 1101 [Iqu… 1 [Urb…
6 10013 110110060201 1510 1 [1 Región … 11 [11 I… 1101 [Iqu… 1 [Urb…
# ℹ 256 more variables: sexo.x <dbl+lbl>, fexp <dbl>, p1 <dbl+lbl>,
# p2 <dbl+lbl>, p3 <dbl+lbl>, p4 <dbl+lbl>, p11 <dbl+lbl>, p12 <dbl+lbl>,
# l0 <dbl>, l1 <dbl>, l2 <dbl+lbl>, l3 <dbl>, l4_1 <dbl+lbl>, l4_2 <dbl+lbl>,
# l4_3 <dbl+lbl>, l4_4 <dbl+lbl>, l4_5 <dbl+lbl>, l4_6 <dbl+lbl>,
# l5 <dbl+lbl>, l6 <dbl+lbl>, l7 <dbl+lbl>, l8 <dbl+lbl>, l9 <dbl+lbl>,
# l10a <dbl+lbl>, l10b <dbl+lbl>, l11 <dbl+lbl>, l12 <dbl+lbl>,
# tramoebs1 <dbl+lbl>, disc <dbl+lbl>, neduc_ebs <dbl+lbl>, a1 <dbl+lbl>, …Por último, verificamos que se mantenga la cantidad de casos original de la EBS como mencionamos antes.
dim(datos_proc) [1] 10921 263Mantenemos 10.921 personas.
Ahora que ya tenemos una base final con información de la EBS y CASEN 2020, podemos continuar con los demás procesamientos necesarios para nuestra investigación.